
Sensor fusion in a nutshell is about combining the information from multiple different sensors in order to obtain a more accurate picture than any single sensor could provide by itself. For example, autonomous land vehicles need to accurately determine their own position, orientation, and state of motion with respect to their surroundings. They also need to have accurate information of all other dynamic actors in their vicinity, such as pedestrians and other automobiles.
From a theoretical point of view, sensor fusion is firmly based on understanding probability as a state of knowledge, which allows us to combine and manipulate different sources of information via the methods of Bayesian statistics. From a more practical point of view, real-time numerical sensor fusion is viable primarily because Bayesian combinations of Gaussian probability densities yield Gaussian densities as a result. Thus if we can approximate our current state of knowledge and the incoming information using Gaussian probability densities, we can leverage analytical formulae and numerical linear algebra. This allows us to efficiently compute our updated state of knowledge.
In this blog article, I will briefly review some of the basic mathematical and statistical building blocks of sensor fusion. As an AI scientist with a background in applied mathematics and theoretical physics, my intention is to provide some condensed, yet precise glimpses into the theoretical machinery that powers sensor fusion. We have covered sensor fusion and its real-world applications from a general point of view in our previous blog article.
Combining information the probabilistic way
The goal in sensor fusion applications is typically to obtain an accurate estimate of the state of some system. The state is usually most conveniently represented by a ?-dimensional vector, 𝑥∈ℝ𝑛. The vector could contain for example the position and orientation and their derivatives of an autonomous vehicle, with respect to some coordinate system. We can use 𝐻𝑥 to denote the proposition that the state vector is ? (see [1] for some technical details we are omitting). Further, we set ? to denote the data we have just obtained, and use ? to denote any other information relevant to the problem we might have.
We are ultimately interested in the quantity 𝑃(𝐻𝑥|𝐷𝐼), or the probability that the state is ?, conditional to the data and everything else we know about the problem. Typically, we are dealing with continuous state variables, such as the position or velocity of a moving vehicle. In the continuous case, the object of interest is actually the probability density 𝑓𝐻(𝑥|𝐷𝐼) of the state ?.
To get there, we can start from the probability that both 𝐻𝑥 and ? are true, 𝑃(𝐻𝑥𝐷|𝐼). Using the product rule of Bayesian theory we can write this in two equivalent forms
?(?_??|?) = ?(?_?|??)?(?|?) = ?(?|?_??)?(?_?|?), (1)
from which we find
?(?_?|??) = {?(?|?_??) ?(?_?|?)}{?(?|?)}, (2)
which is known as the Bayes’ theorem.
The role of ?(?|?) in sensor fusion applications is mainly as a normalization constant, which, if necessary, we can obtain from $$?(?|?) = \int ?(?|?_??)?(?_?|?)\mathrm{d}?, \quad(3)$$ with a slight abuse of notation, since the $latex \{?_?|? \in\mathbb{R}^n\}$ are assumed to be a mutually exclusive and exhaustive set of propositions. Likewise, unless we really do have some relevant prior information, the prior distribution $latex ?(?_?|?)$ can be assumed to be non-informative, typically a constant as well. The end result is that we find $$?(?_?|??) \propto ?(?|?_??), \quad (4)$$ or that the posterior probability is proportional to the likelihood.
Now, the main point of sensor fusion is that we are combining data from multiple sensors. So let us set that $latex ? = ?_? ?_?$, by which we denote that we have obtained a datum both from sensor ? as well as sensor ?. We will keep referring to only these two sensors although everything in the following readily generalizes for any number of simultaneous measurements.
Using the product law, we then have $$?(?_??_?|?_??) = ?(D_?|?_??_??)?(?_?|?_??) = ?(?_?|?_??)?(?_?|?_??), \quad (5)$$ where in the last equality we have assumed the measurements to be statistically independent. We are finally left with $$?(?_?|??) \propto ?(?_?|?_??)?(?_?|?_??),\quad (6)$$ or that the posterior probability is proportional to the product of the data likelihoods. Correspondingly, for the probability density of the state we have $$?_?(?|??) \propto ?(?_?|?_??)?(?_?|?_??).\quad (7)$$
Gaussians in, Gaussians out
To proceed further we need to be able to make sense of the likelihoods $latex ?(?|?_??)$. This amounts to specifying how a particular state ? and a particular measurement are related, probabilistically. For the sake of this blog article, we are making the simplifying assumption that the measurements 𝑧∈ℝ𝑛 from all sensors belong to the same space ℝ? as our state (see e.g. [2] for when this is not the case).
Since the sensor readouts typically are also real numbers of sets of real numbers, we can denote e.g. $latex ?_{?,?}$ to mean the proposition that the sensor ? produced a value ?. Defining a probability density $latex f_?(?|?)$ parametrized by the state then allows us to write the likelihoods as $$?(?_{?,?}|?_??) \propto ?_?(?|?).\quad (8)$$
For practical computations, the sensor likelihoods, $latex f_?$ and $latex ?_?$ for the sensors ? and ? need to have a computationally suitable representation. Turns out that Gaussian densities are extremely convenient for this purpose and also often correspond reasonably well to the real-world properties of measurements. As such, we choose to represent the measurement likelihoods as $$?_?(?|?) = \mathcal{N} (?; ?, ?_?),\quad (9)$$ where $latex \mathcal{N} (?; ?, ?_?)$ is the Gaussian probability density of a multivariate normal distribution with a mean of ? and a covariance matrix of $latex ?_?$. Here z represents the measured value and the covariance matrix represents the measurement uncertainty. The case for sensor ? is naturally identical.
We can now leverage the properties of Gaussian densities which gives us $$\mathcal{N} (?_?; ?, ?_?) \mathcal{N} (?_?; ?, ?_?) \propto \mathcal{N} (?; ?, ?),\quad (10)$$ where $latex ? = ?(?^{-1}_? ?_? + ?^{−1}_? ?_?)$ is the effective measurement value and $latex ? = (?^{−1}_? + ?^{−1}_? )^{−1}$ is an effective measurement covariance. Thus the product of Gaussian sensor likelihoods is proportional to a single Gaussian density, with an effective measured value that is a weighted mean of the individual sensor measurements. For a graphical representation of this phenomenon, see Figure 1.
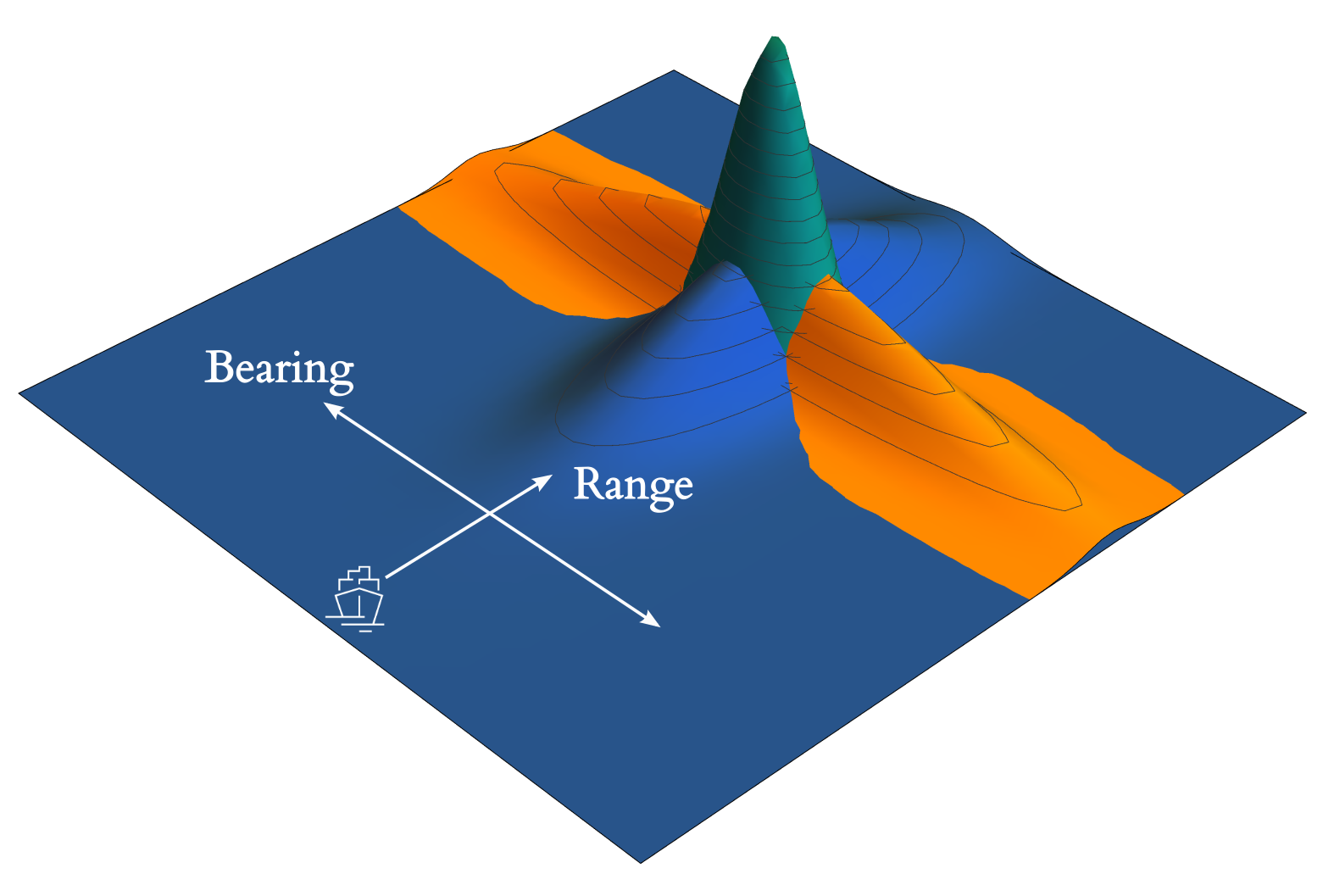
The benefits of sensor fusion
While it is clear that the property of products of Gaussians to yield a single Gaussian is useful from a numerical point of view, it is also useful for inferences in general. If we consider instead of two different sensors some larger number ? of different sensors, the generalization of equation (10) yields $$? = ?\sum_{i=1}^N ?^{−1}_? ?_? \quad (11)$$ $$?=\left( \sum_{i=1}^N ?^{−1}_?\right)^{−1}.\quad (12)$$
From equation (11) we see that any measurement $latex ?_?$ with a particularly large uncertainty is automatically discounted in the computation of the effective measured value. This is caused by the inverse $latex ?^{−1}_?$ yielding a small contribution for the product $latex ?^{−1}_? ?_?$. This is one of the tangible benefits of sensor fusion.
In addition, we see from equation (12) that even if all $latex ?_?$ are equal, we still have $latex ? = (\sum_i ?_?)/?$ and $latex ? = ?_?/?$, or that covariance of the effective measurement is reduced by a factor of 1/? compared to the incoming measurements. This is essentially the 1/√? law of averaging independent measurements in action and is a further advantage of sensor fusion.
However, if the different sensors can produce results that have geometrically advantageous distributions with respect to each other, as in Figure 1., the resulting uncertainty in the effective measured value can be much smaller as a result. In these cases, our state of knowledge is greatly enhanced by combining separate uncertain but complementary measurements, and this is what sensor fusion is really all about.
Personal reflections
On a personal level, I have had the opportunity to work with sensor fusion algorithms in a variety of different contexts. These include industrial measurement systems, satellite radar, and most recently at Silo AI, working with maritime Augmented Reality (AR) systems together with Groke Technologies. Across these projects, the same fundamental principles of sensor fusion apply due to the common unifying theme of dynamics and combination of different sources of information. This is despite the fact that the state representations, data, and sensors can be quite different in these different contexts. I have been positively surprised time after time how smoothly such abstract – and some could argue abstruse – mathematical concepts as forms, metrics, entropy, and information translate into powerful numerical algorithms powering our modern civilization.
I personally consider sensor fusion a fascinating field, with a rare combination of some fundamentals of probability theory, a hefty dose of applied mathematics, and plenty of important real-world applications. However, in this article, we have out of necessity only very thinly scraped the surface of sensor fusion. As such, there are several interesting facets of sensor fusion that we have not mentioned at all.
For example, we have not touched on the question of how information is propagated through time – an aspect that is crucial for most real-life scenarios. In practice, measurement data comes in as timed sequences, and we wish to constantly update our information to correspond to the present moment based on the latest measurements. This is a topic commonly referred to as filtering, with the main tool in the field being the ubiquitous Kalman filter. However, covering the Kalman filter in all its interesting detail would require a whole blog article of its own. Fortunately, such a blog post already exists, and we refer the reader to the excellent and visually satisfying description [3].
References
[1] Edwin T. Jaynes. Probability Theory – The Logic of Science. Cambridge University Press, Cambridge, United Kingdom, 2019.
[2] Wolfgang Koch. Tracking and Sensor Data Fusion – Methodological Framework and Selected Applications. Springer Verlag, Berlin, Heidelberg, Germany, 2014.
[3] Tim Babb. How a Kalman filter works, in pictures. https://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/
About
Want to discuss how Silo AI could help your organization?


Join the 5000+ subscribers who read the Silo AI monthly newsletter to be among the first to hear about the latest insights, articles, podcast episodes, webinars, and more.


