
Machine learning in embedded systems is becoming increasingly important. We are seeing it being utilized in a multitude of different application areas including automotive, manufacturing, robotics as well as as well as in advanced consumer devices, to name a few. To process data close to its acquisition has multiple benefits, for example, lowering latencies or reducing data transmission bandwidth. This is referred to as edge computing, in comparison to moving data to the remote computer or cloud.
Today, the evolution of processing capabilities provided by the modern embedded computing solutions, from microcontrollers to SoCs (System on a chip) as well as advanced deployment frameworks, are supporting this embedded or edge AI trend. The adoption of these technologies is already happening and will be expanding in the future. In this blog article, I will share my key insights on applying modern AI, such as deep neural networks, into restricted computation environments found in modern embedded and edge devices.
What do we mean by restricted environments?
All computing systems have limitations, but some chipset environments are significantly more challenging than others. Main restrictions rise from hardware specifications, such as limited computing capacity or small memory size. However, other aspects such as power consumption and thermal behavior are also factors that typically need to be taken into account.
Architectures for embedded AI have different capabilities. In this blog post, we will focus on the following embedded AI architectures:
- System on a chip (SoC)
- 32-bit microcontrollers
- 8-bit microcontrollers
Traditionally smartphones and tablets devices can be considered as embedded systems, however, their computational capabilities are already approaching the level of common low-end PCs. SoCs used in these devices also contain graphics processing units (GPU) and dedicated AI accelerators. They are able to run advanced operating systems and have rich connectivity support. Nowadays similar SoCs are used also for industrial applications, automotive, and advanced consumer electronics appliances.
In smaller devices like microcontrollers, there is an evolution towards the adoption of 32-bit architectures, and while still significantly less capable than SoCs they provide an interesting platform for modern data-driven AI solutions, especially in low-power, cost-efficient sensor data processing. Taking a closer look at smaller microcontroller devices it is observed that some modern processing architectures, such as Cortex-M4F have also already advanced operations (dual MAC, SIMD, etc.) that can speed up the execution of the machine learning algorithms.
Nevertheless, we should not overlook the possibility of utilizing advanced data-driven algorithms even in very small older 8-bit architectures. While these systems are naturally quite limited, with proper design and choice of correct machine learning approaches they can be also harnessed to run AI algorithms.
Machine learning in low resource hardware
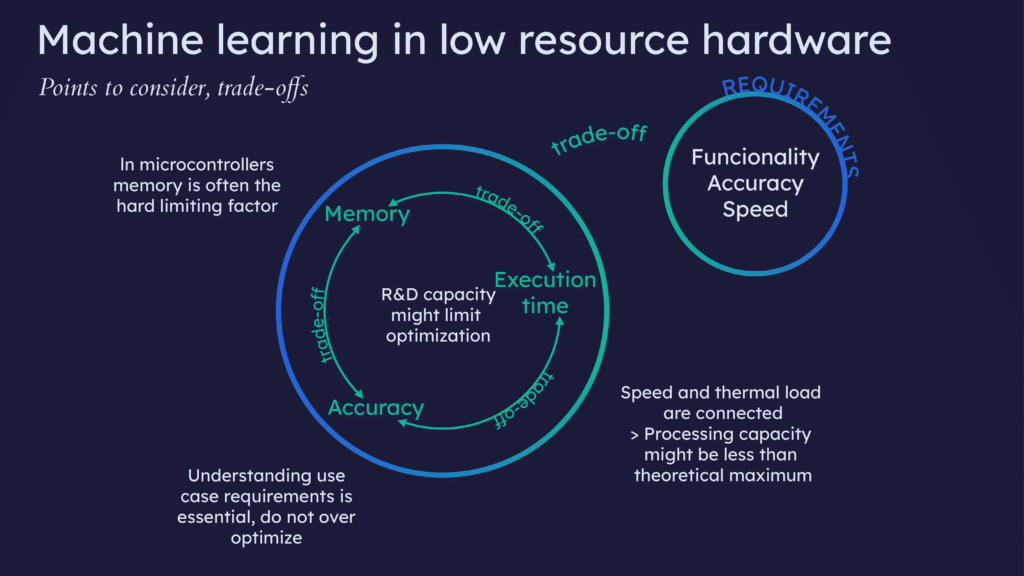
In all product designs, but especially when working with restricted hardware, we at Silo AI consider good R&D practices that embrace system-level thinking crucial. With a limited computing environment, there is typically a need to do design compromises. In order to do these in an optimal and controlled way, it is vital to:
- Understand the use case requirements. This needs to be looked at from both end customers but also from an architecture point of view. Consider factors like functionality, accuracy, speed, latency, maintainability, interfacing, etc. What are the most valuable features that cannot be compromised?
- Identify system limitations. Seek to understand the processing power, memory size, and thermal limits but also restrictions due to the software environment. It is important to look at the total system-level behavior, and not to focus only on the machine learning parts. Eventually, the full product functionality is the sum of all its components and AI needs to be integrated seamlessly as part of the total solution.
- Identify R&D constraints. Consider cost, time-to-market, resources, available competencies, lifetime of the product, etc. Sometimes with limited resources more optimization and tailoring is needed. If highly optimized and proprietary solutions are developed, can it be guaranteed that they can be maintained throughout the whole product life cycle?
AI development for the edge
At the beginning of the practical AI development project, it is important to start with an approximate understanding of the platform’s capabilities and of the complexity of the machine learning solution. It is tempting to jump to development and experimentation with algorithms without any restrictions in an environment like a powerful desktop PC or cloud computing service. This is often justified by the need to first see if the chosen approaches would work for use cases or not. While it is useful to get such quick insight, especially when working with a new problem, there is a risk that a significant R&D effort is spent on solutions that eventually cannot be deployed into target hardware. In order to avoid this, two critical sets of restrictions need to be considered from the beginning:
The first set of restrictions are related to the hardware architecture. For example, in very small devices like microcontrollers, memory, including both program memory used to store the machine learning models and RAM needed for executing those models, are critical. In many use cases with microcontrollers, the processing speed might be less of an issue as the models are relatively small and thus their execution time will not be a bottleneck.
For more capable SoC’s the relevant use cases do often require models that are more complex and input data is large, like images or a video stream. In these cases, the performance is less often restricted by memory, but instead, computational speed, power consumption, or overheating can be the critical limiting factors. Thus, the model complexity must match the hardware capabilities from the start. Trying to modify overly complex machine learning solutions into a limited computing environment is often doomed to failure.
The second design restriction is coming from software. Typically the machine learning frameworks that are optimized for edge computing do not support all features that full versions of the same frameworks are offering. For example, some neural network layer types or activation functions may not be available in the target environment. The problem arises when there is a need to use network architecture with these unsupported features. Luckily, in many cases, modifying some part of the network so that it supports inference on edge devices is possible, but this should be done before considerable effort and time is spent for training the network.
It should be noted that while deployment frameworks are constantly evolving and new features are being added, AI architectures are also evolving rapidly. Sometimes, documentation is lacking behind the actual implementation. Especially in the case of deploying cutting-edge machine learning architecture to an embedded device, it is advisable to verify the support for required features with practical testing with the target platform.
To summarize, it is crucial to start testing AI solutions already at the beginning of the developed project in the targeted hardware and software platform. From a performance point of view, it is also important that the full use case, including data acquisition and pre-processing and application logic, is part of the testing starting from relatively early stages. This ensures that the chosen AI solution can be executed in the final product with the required accuracy and performance.
Hands-on
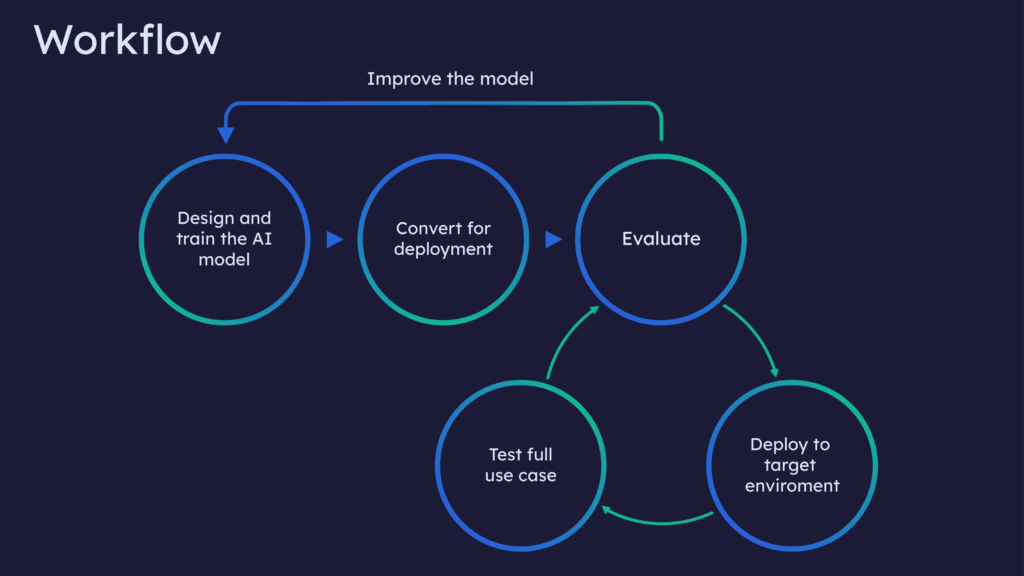
At Silo AI we have worked on customer projects from 8-bit and 32-bit microcontrollers to advanced SoCs with dedicated machine learning accelerators. While each of the customers' case is different and platforms have different toolchains for optimal deployment, the basic AI development flow follows similar steps:
- Machine learning models are developed and trained with common frameworks such as TensorFlow or PyTorch.
- Models are then converted to the format that is more suitable for efficient execution in the target hardware environment. Some platforms have their own format and APIs for this, but many of them are also supporting more generic deployment formats, for example, TensorFlow Lite. In some cases, especially for microcontrollers, the machine learning models are converted directly to executable code to minimize the memory footprint.
- Solutions are tested in the target environment, and if needed model parameters and performance are iterated. Typically in the early phase of the development different architectures are tested in order to find the best alternative for the use case requirements.
Conclusions
We are seeing a bright future for embedded and edge AI. In order to tap the entire potential of these resource restricted environments, it is always important to look at problems holistically, understand use case requirements and consider total system-level architecture. AI is a great tool, but it won’t replace good product development practices.
About
Want to discuss how Silo AI could help your organization?


Join the 5000+ subscribers who read the Silo AI monthly newsletter to be among the first to hear about the latest insights, articles, podcast episodes, webinars, and more.


